Data transformations such as logging or deflating also change the interpretation and standards for R-squared, inasmuch as they change the variance you start out with. In a multiple regression model R-squared is determined by pairwise correlations among allthe variables, including correlations of the independent variables with each other as well as with the dependent variable. It is called R-squared because in a simple regression model it is just the square of the correlation between the dependent and independent variables, which is commonly denoted by “r”. A correlation coefficient gives a numerical summary of the degree of association between two variables – e,g, to what degree do high values of one variable go with high values of the other one?
This yields a list of errors squared, which is then summed and equals the unexplained variance. R-squared (R2) is a statistical measure that represents the proportion of the variance for a dependent variable that’s explained by an independent variable or variables in a regression model. Whereas correlation explains the strength of the relationship between an independent and dependent variable, R-squared explains to what extent the variance of one variable explains the variance of the second variable. So, if the R2of a model is 0.50, then approximately half of the observed variation can be explained by the model’s inputs. Additionally, a form of the Pearson correlation coefficient shows up in regression analysis.
Pearson’s correlation coefficient is represented by the Greek letter rho (ρ) for the population parameter and r for a sample statistic. This correlation coefficient is a single number that measures both the strength and direction of the linear relationship between two continuous variables.
What does the R squared value mean?
R-squared is a statistical measure of how close the data are to the fitted regression line. It is also known as the coefficient of determination, or the coefficient of multiple determination for multiple regression. 100% indicates that the model explains all the variability of the response data around its mean.
It is important to note that there may be a non-linear association between two continuous variables, but computation of a correlation coefficient does not detect this. Therefore, it is always important to evaluate the data carefully before computing a correlation coefficient. Graphical displays are particularly useful to explore associations between variables.
Significance of r or R-squared depends on the strength or the relationship (i.e. rho) and the sample size. If the sample is very large, even a miniscule correlation coefficient may be statistically significant, yet the relationship may have no predictive value. In the case of more than one independent variable, you will have to plot the residuals against the dependent and independent variables to check for non-linearity. The actual calculation of R-squared requires several steps.
If we have more variables that explain changes in weight, we can include them in the model and potentially improve our predictions. And, if the relationship is curved, we can still fit a regression model to the data. Pearson’s correlation coefficients measure only linear relationships. Consequently, if your data contain a curvilinear relationship, the correlation coefficient will not detect it.
R-squared is a primary measure of how well a regression model fits the data. This statistic represents the percentage of variation in one variable that other variables explain. For a pair of variables, R-squared is simply the square of the Pearson’s correlation coefficient.
R-Squared Definition
Correlation coefficients vary from -1 to +1, with positive values indicating an increasing relationship and negative values indicating a decreasing relationship. Is there a pattern in the data that follows a pattern other than linear.
R-Squared only works as intended in a simple linear regression model with one explanatory variable. With a multiple regression made up of several independent variables, the R-Squared must be adjusted. The adjusted R-squared compares the descriptive power of regression models that include diverse numbers of predictors.
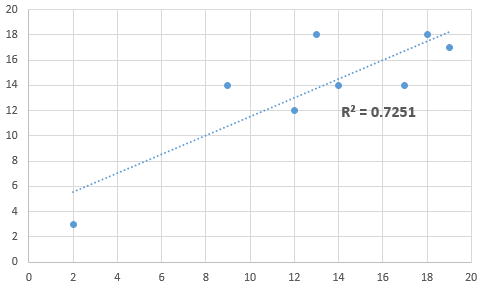
- Significance of r or R-squared depends on the strength or the relationship (i.e. rho) and the sample size.
- In the case of more than one independent variable, you will have to plot the residuals against the dependent and independent variables to check for non-linearity.
For example, squaring the height-weight correlation coefficient of 0.694 produces an R-squared of 0.482, or 48.2%. In other words, height explains about half the variability of weight in preteen girls. A hIgh correlation coefficient just mean that the model that was adopted fits well the data you have. Sometimes this model comes from a physical relationship, sometimes this model is just a mathematical function.
This includes taking the data points (observations) of dependent and independent variables and finding the line of best fit, often from a regression model. From there you would calculate predicted values, subtract actual values and square the results.
What Does R-Squared Tell You?
As far as linear, adding other independent explanatory variables certainly has merit, but the question is which one(s)? Do you have any further information on the data, for example geographic location, time, anything that can use to subgroup the data. There appears to be a relationship with the explanatory variable you’re using, but there’s obviously so much more that’s unexplained by the variables you’re using. Regression analysis allows us to expand on correlation in other ways.
These are unbiased estimators that correct for the sample size and numbers of coefficients estimated. Adjusted R-squared is always smaller than R-squared, but the difference is usually very small unless you are trying to estimate too many coefficients from too small a sample in the presence of too much noise. Specifically, adjusted R-squared is equal to 1 minus (n – 1)/(n – k – 1) times 1-minus-R-squared, where n is the sample size and k is the number of independent variables. In this scatter plot of the independent variable (X) and the dependent variable (Y), the points follow a generally upward trend. If we were to graph a line of best fit, then we would notice that the line has a positive slope.
Therefore, you can obtain a low correlation coefficient, depending on the quality of your data, for a physical derived model and have a high correlatIon coefficient for a mathematical model you’ve hypotetically conceived. You can obtain a high correlation coefficient for completely disconnected variables. But, being straight in the answer of your question, for cartesians, a high correlation coefficient, as close as to the unity, is sought. For a natural/social/economics science student, a correlation coefficient higher than 0.6 is enough. The correlation, denoted by r, measures the amount of linear association between two variables.r is always between -1 and 1 inclusive.The R-squared value, denoted by R2, is the square of the correlation.
For example, the correlation for the data in the scatterplot below is zero. However, there is a relationship between the two variables—it’s just not linear.
It measures the proportion of variation in the dependent variable that can be attributed to the independent variable.The R-squared value R2 is always between 0 and 1 inclusive.Perfect positive linear association. Don’t ever let yourself fall into the trap of fitting (and then promoting!) a regression model that has a respectable-looking R-squared but is actually very much inferior to a simple time series model. If the dependent variable in your model is a nonstationary time series, be sure that you do a comparison of error measures against an appropriate time series model. In fact, an R-squared of 10% or even less could have some information value when you are looking for a weak signal in the presence of a lot of noise in a setting where even a veryweak one would be of general interest. Sometimes there is a lot of value in explaining only a very small fraction of the variance, and sometimes there isn’t.
The Difference Between R-Squared and Beta
Every predictor added to a model increases R-squared and never decreases it. In anoverfittingcondition, an incorrectly high value of R-squared is obtained, even when the model actually has a decreased ability to predict.
What is the Difference Between R-Squared and Adjusted R-Squared?
R-squared will give you an estimate of the relationship between movements of a dependent variable based on an independent variable’s movements. It doesn’t tell you whether your chosen model is good or bad, nor will it tell you whether the data and predictions are biased. A high or low R-square isn’t necessarily good or bad, as it doesn’t convey the reliability of the model, nor whether you’ve chosen the right regression. You can get a low R-squared for a good model, or a high R-square for a poorly fitted model, and vice versa.
I added a paragraph pointing out that with linear regression, R2 can be negative only when the intercept (or perhaps the slope) is constrained. With no constraints, the R2 must be positive and equals the square of r, the correlation coefficient.