The P value is a function of the R2, the number of observations, and the number of X variables. R-squared will give you an estimate of the relationship between movements of a dependent variable based on an independent variable’s movements. It doesn’t tell you whether your chosen model is good or bad, nor will it tell you whether the data and predictions are biased.
Because most humans have a hard time visualizing four or more dimensions, there’s no good visual way to summarize all the information in a multiple regression with three or more independent variables. Another assumption of multiple regression is that the X variables are not multicollinear. Multicollinearity occurs when two independent variables are highly correlated with each other. For example, let’s say you included both height and arm length as independent variables in a multiple regression with vertical leap as the dependent variable.
What is the regression line?
A regression line is simply a single line that best fits the data (in terms of having the smallest overall distance from the line to the points). The formula for the best-fitting line (or regression line) is y = mx + b, where m is the slope of the line and b is the y-intercept.
The regression model tells you the significance of each IV after accounting for the variance that the other IVs explain. When a model excludes an important variable, it potentially biases the relationships for the variables in the model. For more information, read my post about omitted variable bias. That post tells you more about it along with conditions under which it can occur.
This yields a list of errors squared, which is then summed and equals the unexplained variance. Multiple regression generally explains the relationship between multiple independent or predictor variables and one dependent or criterion variable.
What does a regression line tell you?
A regression line is a straight line that de- scribes how a response variable y changes as an explanatory variable x changes. We often use a regression line to predict the value of y for a given value of x. Note.
The result is a linear regression equation that can be used to make predictions about data. You need to have several times as many observations as you have independent variables, otherwise you can get “overfitting”—it could look like every independent variable is important, even if they’re not. A common rule of thumb is that you should have at least 10 to 20 times as many observations as you have independent variables. You’ll probably just want to collect as much data as you can afford, but if you really need to figure out how to do a formal power analysis for multiple regression, Kelley and Maxwell is a good place to start. If the multiple regression equation ends up with only two independent variables, you might be able to draw a three-dimensional graph of the relationship.
Linear Regression: Simple Steps, Video. Find Equation, Coefficient, Slope
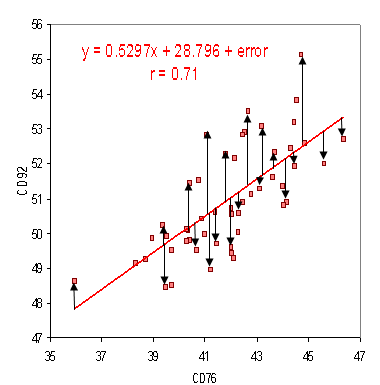
However, many people are skeptical of the usefulness of multiple regression, especially for variable selection. This means that different researchers, using the same data, could come up with different results based on their biases, preconceived notions, and guesses; many people would be upset by this subjectivity. Every time you add a variable to a multiple regression, the R2 increases (unless the variable is a simple linear function of one of the other variables, in which case R2 will stay the same). The best-fitting model is therefore the one that includes all of the X variables. However, whether the purpose of a multiple regression is prediction or understanding functional relationships, you’ll usually want to decide which variables are important and which are unimportant.
Because height and arm length are highly correlated with each other, having both height and arm length in your multiple regression equation may only slightly improve the R2 over an equation with just height. So you might conclude that height is highly influential on vertical leap, while arm length is unimportant. It is easy to throw a big data set at a multiple regression and get an impressive-looking output.
Linear Regression Equation Microsoft Excel: Steps
You’re probably familiar with plotting line graphs with one X axis and one Y axis. The X variable is sometimes called the independent variable and the Y variable is called the dependent variable.
- R-Squared only works as intended in a simple linear regression model with one explanatory variable.
Simple linear regression plots one independent variable X against one dependent variable Y. Technically, in regression analysis, the independent variable is usually called the predictor variable and the dependent variable is called the criterion variable. However, many people just call them the independent and dependent variables. More advanced regression techniques (like multiple regression) use multiple independent variables. It also assumes that each independent variable would be linearly related to the dependent variable, if all the other independent variables were held constant.
Finding the slope of a regression line
For example, let’s say you’re interested in finding suitable habitat to reintroduce the rare beach tiger beetle, Cicindela dorsalis dorsalis, which lives on sandy beaches on the Atlantic coast of North America. Multiple regression would give you an equation that would relate the tiger beetle density to a function of all the other variables. This could help you guide your conservation efforts, so you don’t waste resources introducing tiger beetles to beaches that won’t support very many of them. This includes taking the data points (observations) of dependent and independent variables and finding the line of best fit, often from a regression model. From there you would calculate predicted values, subtract actual values and square the results.
Before doing multiple regression, you should check the correlation between each pair of independent variables, and if two are highly correlated, you may want to pick just one. Atlantic beach tiger beetle, Cicindela dorsalis dorsalis.One use of multiple regression is prediction or estimation of an unknown Y value corresponding to a set of X values.
This discrepancy sounds like a form of omitted variable bias. You have to remember that these two analyses are testing different models. Pairwise correlation only assesses two variables at a time while your multiple regression model has at least two independent variables and the dependent variable.
Statistics for the rest of us!
The first step in finding a linear regression equation is to determine if there is a relationship between the two variables. You’ll also need a list of your data in x-y format (i.e. two columns of data—independent and dependent variables). Linear regression is the most widely used statistical technique; it is a way to model a relationship between two sets of variables.
A dependent variable is modeled as a function of several independent variables with corresponding coefficients, along with the constant term. Multiple regression requires two or more predictor variables, and this is why it is called multiple regression. After fitting a regression model, check the residual plotsfirst to be sure that you have unbiased estimates. Linear regression analysis can produce a lot of results, which I’ll help you navigate. In this post, I cover interpreting the p-values and coefficients for the independent variables.
Every predictor added to a model increases R-squared and never decreases it. In anoverfittingcondition, an incorrectly high value of R-squared is obtained, even when the model actually has a decreased ability to predict. If your goal is prediction, multicollinearity isn’t that important; you’d get just about the same predicted Y values, whether you used height or arm length in your equation. However, if your goal is understanding causes, multicollinearity can confuse you.
The R-squared of the regression is the fraction of the variation in your dependent variable that is accounted for (or predicted by) your independent variables. The P value tells you how confident you can be that each individual variable has some correlation with the dependent variable, which is the important thing. These are the values that the procedure estimates from your data. In a regression equation, these values multiply the independent variables.
So, if the R2of a model is 0.50, then approximately half of the observed variation can be explained by the model’s inputs. The two basic types of regression are simple linear regression and multiple linear regression, although there are non-linear regression methods for more complicated data and analysis. Simple linear regression uses one independent variable to explain or predict the outcome of the dependent variable Y, while multiple linear regression uses two or more independent variables to predict the outcome.
A high or low R-square isn’t necessarily good or bad, as it doesn’t convey the reliability of the model, nor whether you’ve chosen the right regression. You can get a low R-squared for a good model, or a high R-square for a poorly fitted model, and vice versa. R-squared (R2) is a statistical measure that represents the proportion of the variance for a dependent variable that’s explained by an independent variable or variables in a regression model. Whereas correlation explains the strength of the relationship between an independent and dependent variable, R-squared explains to what extent the variance of one variable explains the variance of the second variable.
R-Squared only works as intended in a simple linear regression model with one explanatory variable. With a multiple regression made up of several independent variables, the R-Squared must be adjusted. The adjusted R-squared compares the descriptive power of regression models that include diverse numbers of predictors.